Extract features¶
[1]:
import movekit as mkit
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import animation
[2]:
# Enter path to CSV file
path = "./datasets/fish-5-cleaned.csv"
data = mkit.read_data(path)
data.head()
[2]:
| time | animal_id | x | y | |
|---|---|---|---|---|
| 0 | 1 | 312 | 405.29 | 417.76 |
| 1 | 1 | 511 | 369.99 | 428.78 |
| 2 | 1 | 607 | 390.33 | 405.89 |
| 3 | 1 | 811 | 445.15 | 411.94 |
| 4 | 1 | 905 | 366.06 | 451.76 |
Extract features from preprocessed data for each animal: Distance, Average Speed, Average Acceleration, Direction, Stopped, Turning angle¶
[3]:
# Extract additional features from the preprocessed movement data: Distance traveled between two timestamps, average speed between two timestamps, average acceleration between two timestamps, direction of the mover, whether the mover stopped at time stamp, and the turning angle of the mover at time stamp.
#Parameters:
# data: pandas DataFrame with all records of movements.
# fps: window size for average_speed and average_acceleration calculations. For integer-time type of fps is integer, otherwise type of fps is string.
# stop_threshold: integer to specify threshold for average speed, such that mover is considered to make a "stop".
data_features = mkit.extract_features(data, fps = 3, stop_threshold = 0.2)
data_features.head(20)
Extracting all absolute features: 100%|██████████| 100.0/100 [00:01<00:00, 52.82it/s]
[3]:
| time | animal_id | x | y | distance | direction | turning | average_speed | average_acceleration | stopped | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 312 | 405.29 | 417.76 | 0.000000 | (0.0, 0.0) | 0.000000 | 0.180171 | 0.027515 | 1 |
| 1 | 1 | 511 | 369.99 | 428.78 | 0.000000 | (0.0, 0.0) | 0.000000 | 0.019907 | 0.001813 | 1 |
| 2 | 1 | 607 | 390.33 | 405.89 | 0.000000 | (0.0, 0.0) | 0.000000 | 0.040104 | 0.013106 | 1 |
| 3 | 1 | 811 | 445.15 | 411.94 | 0.000000 | (0.0, 0.0) | 0.000000 | 0.228980 | 0.064587 | 0 |
| 4 | 1 | 905 | 366.06 | 451.76 | 0.000000 | (0.0, 0.0) | 0.000000 | 0.093333 | 0.016944 | 1 |
| 5 | 2 | 312 | 405.31 | 417.37 | 0.390512 | (0.02, -0.39) | 0.000000 | 0.265210 | 0.014511 | 0 |
| 6 | 2 | 511 | 370.01 | 428.82 | 0.044721 | (0.02, 0.04) | 0.000000 | 0.026574 | 0.000505 | 1 |
| 7 | 2 | 607 | 390.25 | 405.89 | 0.080000 | (-0.08, 0.0) | 0.000000 | 0.070208 | 0.017008 | 1 |
| 8 | 2 | 811 | 445.48 | 412.26 | 0.459674 | (0.33, 0.32) | 0.000000 | 0.382856 | 0.078737 | 0 |
| 9 | 2 | 905 | 365.86 | 451.76 | 0.200000 | (-0.2, 0.0) | 0.000000 | 0.141667 | 0.012778 | 1 |
| 10 | 3 | 312 | 405.31 | 417.07 | 0.300000 | (0.0, -0.3) | 0.998688 | 0.260220 | -0.021231 | 0 |
| 11 | 3 | 511 | 370.01 | 428.85 | 0.030000 | (0.0, 0.03) | 0.894427 | 0.024120 | -0.001373 | 1 |
| 12 | 3 | 607 | 390.17 | 405.88 | 0.080623 | (-0.08, -0.01) | 0.992278 | 0.088633 | 0.013083 | 1 |
| 13 | 3 | 811 | 445.77 | 412.61 | 0.454533 | (0.29, 0.35) | 0.994081 | 0.462626 | 0.055248 | 0 |
| 14 | 3 | 905 | 365.70 | 451.76 | 0.160000 | (-0.16, 0.0) | 1.000000 | 0.146667 | -0.005000 | 1 |
| 15 | 4 | 312 | 405.30 | 416.86 | 0.210238 | (-0.01, -0.21) | 0.998868 | 0.187187 | -0.050651 | 1 |
| 16 | 4 | 511 | 370.01 | 428.86 | 0.010000 | (0.0, 0.01) | 1.000000 | 0.018727 | -0.001601 | 1 |
| 17 | 4 | 607 | 390.07 | 405.88 | 0.100000 | (-0.1, 0.0) | 0.992278 | 0.093622 | 0.004977 | 1 |
| 18 | 4 | 811 | 446.03 | 413.00 | 0.468722 | (0.26, 0.39) | 0.994605 | 0.467753 | 0.019630 | 0 |
| 19 | 4 | 905 | 365.57 | 451.76 | 0.130000 | (-0.13, 0.0) | 1.000000 | 0.116667 | -0.023333 | 1 |
For two-dimensional data one can also compute the direction and the turning angle of a mover.
[4]:
angle_data = mkit.compute_direction_angle(data_features).head(10)
mkit.compute_turning_angle(angle_data)
[4]:
| time | animal_id | x | y | distance | direction | turning | average_speed | average_acceleration | stopped | direction_angle | turning_angle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 312 | 405.29 | 417.76 | 0.000000 | (0.0, 0.0) | 0.0 | 0.180171 | 0.027515 | 1 | 0.000000 | NaN |
| 1 | 1 | 511 | 369.99 | 428.78 | 0.000000 | (0.0, 0.0) | 0.0 | 0.019907 | 0.001813 | 1 | 0.000000 | NaN |
| 2 | 1 | 607 | 390.33 | 405.89 | 0.000000 | (0.0, 0.0) | 0.0 | 0.040104 | 0.013106 | 1 | 0.000000 | NaN |
| 3 | 1 | 811 | 445.15 | 411.94 | 0.000000 | (0.0, 0.0) | 0.0 | 0.228980 | 0.064587 | 0 | 0.000000 | NaN |
| 4 | 1 | 905 | 366.06 | 451.76 | 0.000000 | (0.0, 0.0) | 0.0 | 0.093333 | 0.016944 | 1 | 0.000000 | NaN |
| 5 | 2 | 312 | 405.31 | 417.37 | 0.390512 | (0.02, -0.39) | 0.0 | 0.265210 | 0.014511 | 0 | 272.935673 | 87.064327 |
| 6 | 2 | 511 | 370.01 | 428.82 | 0.044721 | (0.02, 0.04) | 0.0 | 0.026574 | 0.000505 | 1 | 63.434949 | 63.434949 |
| 7 | 2 | 607 | 390.25 | 405.89 | 0.080000 | (-0.08, 0.0) | 0.0 | 0.070208 | 0.017008 | 1 | 180.000000 | 180.000000 |
| 8 | 2 | 811 | 445.48 | 412.26 | 0.459674 | (0.33, 0.32) | 0.0 | 0.382856 | 0.078737 | 0 | 44.118596 | 44.118596 |
| 9 | 2 | 905 | 365.86 | 451.76 | 0.200000 | (-0.2, 0.0) | 0.0 | 0.141667 | 0.012778 | 1 | 180.000000 | 180.000000 |
Computing distances between movers and between timestamps¶
Calculate the euclidean distance between different movers
[5]:
mkit.euclidean_dist(data)
Computing euclidean distance: 100%|██████████| 1000/1000 [00:02<00:00, 421.32it/s]
[5]:
| time | animal_id | x | y | 312 | 511 | 607 | 811 | 905 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 312 | 405.29 | 417.76 | 0.000000 | 36.980135 | 19.097081 | 40.282651 | 51.913321 |
| 1 | 1 | 511 | 369.99 | 428.78 | 36.980135 | 0.000000 | 30.621360 | 77.023446 | 23.313629 |
| 2 | 1 | 607 | 390.33 | 405.89 | 19.097081 | 30.621360 | 0.000000 | 55.152832 | 51.894988 |
| 3 | 1 | 811 | 445.15 | 411.94 | 40.282651 | 77.023446 | 55.152832 | 0.000000 | 88.548634 |
| 4 | 1 | 905 | 366.06 | 451.76 | 51.913321 | 23.313629 | 51.894988 | 88.548634 | 0.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4995 | 1000 | 312 | 720.96 | 244.60 | 0.000000 | 61.509642 | 51.770954 | 75.437726 | 73.481324 |
| 4996 | 1000 | 511 | 662.56 | 225.29 | 61.509642 | 0.000000 | 93.117875 | 129.431823 | 43.068319 |
| 4997 | 1000 | 607 | 722.75 | 296.34 | 51.770954 | 93.117875 | 0.000000 | 41.259047 | 119.983706 |
| 4998 | 1000 | 811 | 762.44 | 307.61 | 75.437726 | 129.431823 | 41.259047 | 0.000000 | 148.883426 |
| 4999 | 1000 | 905 | 677.91 | 185.05 | 73.481324 | 43.068319 | 119.983706 | 148.883426 | 0.000000 |
5000 rows × 9 columns
Compute the euclidean distance between positions for a particular time window for all movers.
[6]:
mkit.distance_by_time(data, 3, 5)
[6]:
| animal_id | distance | |
|---|---|---|
| 0 | 312 | 0.660571 |
| 1 | 511 | 0.060000 |
| 2 | 607 | 0.271176 |
| 3 | 811 | 1.392829 |
| 4 | 905 | 0.390000 |
Additionally one can obtain a matrix of the trajectory similarities, based on the Hausdorff distance of trajectories of the animals.
[7]:
mkit.hausdorff_distance(data)
[7]:
| 312 | 511 | 607 | 811 | 905 | |
|---|---|---|---|---|---|
| 312 | 0.000000 | 61.836554 | 54.412682 | 75.437726 | 73.481324 |
| 511 | 61.836554 | 0.000000 | 93.117875 | 129.431823 | 43.068319 |
| 607 | 54.412682 | 93.117875 | 0.000000 | 83.522165 | 119.983706 |
| 811 | 75.437726 | 129.431823 | 83.522165 | 0.000000 | 148.883426 |
| 905 | 73.481324 | 43.068319 | 119.983706 | 148.883426 | 0.000000 |
Computing centroids and medoids for each time stamp¶
[8]:
#Calculates the data point (animal_id) closest to center/centroid/medoid for each time step.
mkit.centroid_medoid_computation(data, object_output = False)
Calculating centroid distances: 100%|██████████| 1000/1000 [00:05<00:00, 184.80it/s]
[8]:
| time | animal_id | x | y | x_centroid | y_centroid | medoid | distance_to_centroid | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 312 | 405.29 | 417.76 | 395.364 | 423.226 | 312 | 11.331 |
| 1 | 1 | 511 | 369.99 | 428.78 | 395.364 | 423.226 | 312 | 25.975 |
| 2 | 1 | 607 | 390.33 | 405.89 | 395.364 | 423.226 | 312 | 18.052 |
| 3 | 1 | 811 | 445.15 | 411.94 | 395.364 | 423.226 | 312 | 51.049 |
| 4 | 1 | 905 | 366.06 | 451.76 | 395.364 | 423.226 | 312 | 40.901 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4995 | 1000 | 312 | 720.96 | 244.60 | 709.324 | 251.778 | 312 | 13.672 |
| 4996 | 1000 | 511 | 662.56 | 225.29 | 709.324 | 251.778 | 312 | 53.745 |
| 4997 | 1000 | 607 | 722.75 | 296.34 | 709.324 | 251.778 | 312 | 46.541 |
| 4998 | 1000 | 811 | 762.44 | 307.61 | 709.324 | 251.778 | 312 | 77.062 |
| 4999 | 1000 | 905 | 677.91 | 185.05 | 709.324 | 251.778 | 312 | 73.753 |
5000 rows × 8 columns
Exploring the geospatial features and plotting the data¶
One possibility is to plot the movement from all movers/animals in the DataFrame.
[9]:
# plot movement from all movers/animals in a specified time period
mkit.plot_movement(data, frm=0, to=1000)
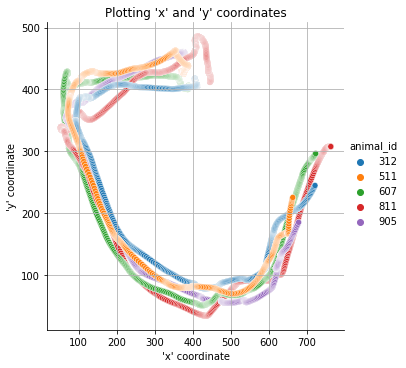
Another option is to plot each individual mover/animal individually.
[10]:
mkit.plot_animal(data, 312)

One can also plot either the average acceleration or the average speed for each individual mover/animal over time.
[11]:
mkit.plot_pace(data_features, "speed")
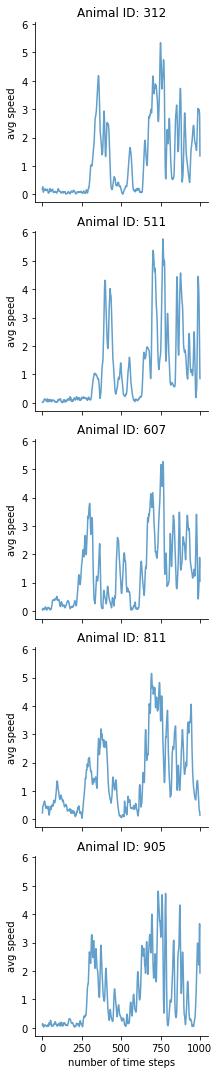
One can additionally check the geospatial distribution of the different movers.
[12]:
#Show exploration of environment space by each animal. Gives singular descriptions of polygon area covered by each animal and combined.
#Additionally a plot of the respective areas is provided.
# mkit.explore_features_geospatial(data)
mkit.explore_features_geospatial(data)
Calculating covered areas: 83%|████████▎ | 83.33333333333334/100 [00:00<00:00, 438.79it/s]
Area (polygon) covered by animal ID = 312 is = 139873.97 sq. units
Area (polygon) covered by animal ID = 511 is = 151556.80 sq. units
Area (polygon) covered by animal ID = 607 is = 171971.54 sq. units
Area (polygon) covered by animal ID = 811 is = 196394.24 sq. units
Area (polygon) covered by animal ID = 905 is = 151805.74 sq. units
Area (polygon) covered by animals collectively is = 214704.49029999992 sq. units

Calculating covered areas: 100%|██████████| 100.00000000000001/100 [00:00<00:00, 179.69it/s]
The data can also be animated.
[ ]:
%matplotlib widget
# animate the data
anim = mkit.animate_movement(data, viewsize = 100)

[ ]:
# one can save the created animation as gif and mp4
# mkit.save_animation_plot(anim, 'movers_animation')
Splitting the trajectory of each animal in stopping and moving phases and analyze their respective duration¶
[19]:
phases_dict = mkit.split_movement_trajectory(data_features, stop_threshold = 0.5)
For animal 312 the trajectory was split in 20 phases of moving and stopping.
For animal 511 the trajectory was split in 14 phases of moving and stopping.
For animal 607 the trajectory was split in 24 phases of moving and stopping.
For animal 811 the trajectory was split in 14 phases of moving and stopping.
For animal 905 the trajectory was split in 22 phases of moving and stopping.
[20]:
phases_dict[312][1] # dataframe of first moving phase of animal 312
[20]:
| time | animal_id | x | y | distance | direction | turning | average_speed | average_acceleration | stopped | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 312 | 405.31 | 417.37 | 0.390512 | (0.02, -0.39) | 0.000000 | 0.26521 | 0.014511 | 0 |
| 1 | 3 | 312 | 405.31 | 417.07 | 0.300000 | (0.0, -0.3) | 0.998688 | 0.26022 | -0.021231 | 0 |
[21]:
duration_dict = mkit.movement_stopping_durations(data_features, stop_threshold = 0.5)
duration_dict[312] # duration of phases for animal 312
For animal 312 the trajectory was split in 20 phases of moving and stopping.
For animal 511 the trajectory was split in 14 phases of moving and stopping.
For animal 607 the trajectory was split in 24 phases of moving and stopping.
For animal 811 the trajectory was split in 14 phases of moving and stopping.
For animal 905 the trajectory was split in 22 phases of moving and stopping.
[21]:
| animal_id | Duration of phase 1 (stopping) | Duration of phase 2 (moving) | Duration of phase 3 (stopping) | Duration of phase 4 (moving) | Duration of phase 5 (stopping) | Duration of phase 6 (moving) | Duration of phase 7 (stopping) | Duration of phase 8 (moving) | Duration of phase 9 (stopping) | ... | Duration of phase 11 (stopping) | Duration of phase 12 (moving) | Duration of phase 13 (stopping) | Duration of phase 14 (moving) | Duration of phase 15 (stopping) | Duration of phase 16 (moving) | Duration of phase 17 (stopping) | Duration of phase 18 (moving) | Duration of phase 19 (stopping) | Duration of phase 20 (moving) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 312 | 1 | 2 | 43 | 2 | 52 | 1 | 190 | 147 | 6 | ... | 26 | 52 | 24 | 1 | 5 | 2 | 5 | 1 | 21 | 365 |
1 rows × 21 columns
Time series analysis¶
Possible parameters to extract time series features are:
absolute_sum_of_changes(x) Returns the sum over the absolute value of consecutive changes in the series x
agg_autocorrelation(x, param) Calculates the value of an aggregation function f_{agg}
agg_linear_trend(x, param) Calculates a linear least-squares regression for values of the time series that were aggregated over chunks versus the sequence from 0 up to the number of chunks minus one.
approximate_entropy(x, m, r) Implements a vectorized Approximate entropy algorithm.
ar_coefficient(x, param) This feature calculator fits the unconditional maximum likelihood of an autoregressive AR(k) process.
augmented_dickey_fuller(x, param) The Augmented Dickey-Fuller test is a hypothesis test which checks whether a unit root is present in a time series sample.
autocorrelation(x, lag) Calculates the autocorrelation of the specified lag, according to the formula [1]
has_duplicate(x) Checks if any value in x occurs more than once
kurtosis(x) Returns the kurtosis of x (calculated with the adjusted Fisher-Pearson standardized moment coefficient G2).
large_standard_deviation(x, r) Boolean variable denoting if the standard dev of x is higher than ‘r’ times the range = difference between max and min of x.
last_location_of_maximum(x) Returns the relative last location of the maximum value of x.
length(x) Returns the length of x
linear_trend(x, param) Calculate a linear least-squares regression for the values of the time series versus the sequence from 0 to length of the time series minus one.
maximum(x) Calculates the highest value of the time series x.
mean(x) Returns the mean of x
median(x) Returns the median of x
minimum(x) Calculates the lowest value of the time series x.
number_crossing_m(x, m) Calculates the number of crossings of x on m.
number_cwt_peaks(x, n) This feature calculator searches for different peaks in x.
number_peaks(x, n) Calculates the number of peaks of at least support n in the time series x.
partial_autocorrelation(x, param) Calculates the value of the partial autocorrelation function at the given lag.
quantile(x, q) Calculates the q quantile of x.
range_count(x, min, max) Count observed values within the interval [min, max].
sample_entropy(x) Calculate and return sample entropy of x.
set_property(key, value) This method returns a decorator that sets the property key of the function to value
skewness(x) Returns the sample skewness of x (calculated with the adjusted Fisher-Pearson standardized moment coefficient G1).
standard_deviation(x) Returns the standard deviation of x
sum_of_reoccurring_data_points(x) Returns the sum of all data points, that are present in the time series more than once.
sum_of_reoccurring_values(x) Returns the sum of all values, that are present in the time series more than once.
sum_values(x) Calculates the sum over the time series values
value_count(x, value) Count occurrences of value in time series x.
variance(x) Returns the variance of x
For all possible features to extract please refer to https://tsfresh.readthedocs.io/en/latest/text/list_of_features.html.
[22]:
#To extract a specific feature from the time series just put the feature name in the function call. The additional parameters needed for the specific feature are inserted automatically by the function.
#For example autocorrelation
#mkit.ts_feature(data, feature)
auto_corr = mkit.ts_feature(data_features, 'autocorrelation')
auto_corr
Feature Extraction: 100%|██████████| 10/10 [00:07<00:00, 1.42it/s]
[22]:
| variable | average_acceleration__autocorrelation__lag_0 | average_acceleration__autocorrelation__lag_1 | average_acceleration__autocorrelation__lag_2 | average_acceleration__autocorrelation__lag_3 | average_acceleration__autocorrelation__lag_4 | average_acceleration__autocorrelation__lag_5 | average_acceleration__autocorrelation__lag_6 | average_acceleration__autocorrelation__lag_7 | average_acceleration__autocorrelation__lag_8 | average_acceleration__autocorrelation__lag_9 | ... | y__autocorrelation__lag_0 | y__autocorrelation__lag_1 | y__autocorrelation__lag_2 | y__autocorrelation__lag_3 | y__autocorrelation__lag_4 | y__autocorrelation__lag_5 | y__autocorrelation__lag_6 | y__autocorrelation__lag_7 | y__autocorrelation__lag_8 | y__autocorrelation__lag_9 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| 312 | 1.0 | 0.952556 | 0.832297 | 0.671888 | 0.495713 | 0.314675 | 0.138799 | -0.020842 | -0.154753 | -0.256890 | ... | 1.0 | 1.000433 | 1.000799 | 1.001097 | 1.001328 | 1.001492 | 1.001589 | 1.001619 | 1.001585 | 1.001487 |
| 511 | 1.0 | 0.962266 | 0.859110 | 0.712870 | 0.545754 | 0.373388 | 0.206931 | 0.054882 | -0.076210 | -0.181685 | ... | 1.0 | 1.000432 | 1.000795 | 1.001090 | 1.001316 | 1.001472 | 1.001556 | 1.001568 | 1.001507 | 1.001375 |
| 607 | 1.0 | 0.944128 | 0.797021 | 0.601672 | 0.397333 | 0.205985 | 0.038301 | -0.098281 | -0.195330 | -0.245064 | ... | 1.0 | 1.000653 | 1.001235 | 1.001747 | 1.002191 | 1.002566 | 1.002874 | 1.003116 | 1.003293 | 1.003406 |
| 811 | 1.0 | 0.933647 | 0.760026 | 0.540593 | 0.331180 | 0.158069 | 0.023213 | -0.078022 | -0.145525 | -0.174610 | ... | 1.0 | 1.000724 | 1.001366 | 1.001928 | 1.002409 | 1.002810 | 1.003132 | 1.003375 | 1.003540 | 1.003628 |
| 905 | 1.0 | 0.937338 | 0.775279 | 0.557322 | 0.322768 | 0.096927 | -0.101056 | -0.258491 | -0.369088 | -0.430305 | ... | 1.0 | 1.000210 | 1.000370 | 1.000482 | 1.000546 | 1.000563 | 1.000537 | 1.000469 | 1.000361 | 1.000215 |
5 rows × 60 columns
Extract all possible time series features
[23]:
#mkit.ts_all_features(data)
#Note that function columnwise replaces all NaNs and infs from the time series results with average/extreme values from the same columns. For more information see https://tsfresh.readthedocs.io/en/v0.5.0/api/tsfresh.utilities.html .
ts_features = mkit.ts_all_features(data_features)
ts_features
Feature Extraction: 100%|██████████| 10/10 [00:31<00:00, 3.16s/it]
[23]:
| turning__variance_larger_than_standard_deviation | turning__has_duplicate_max | turning__has_duplicate_min | turning__has_duplicate | turning__sum_values | turning__abs_energy | turning__mean_abs_change | turning__mean_change | turning__mean_second_derivative_central | turning__median | ... | distance__permutation_entropy__dimension_6__tau_1 | distance__permutation_entropy__dimension_7__tau_1 | distance__query_similarity_count__query_None__threshold_0.0 | distance__matrix_profile__feature_"min"__threshold_0.98 | distance__matrix_profile__feature_"max"__threshold_0.98 | distance__matrix_profile__feature_"mean"__threshold_0.98 | distance__matrix_profile__feature_"median"__threshold_0.98 | distance__matrix_profile__feature_"25"__threshold_0.98 | distance__matrix_profile__feature_"75"__threshold_0.98 | distance__mean_n_absolute_max__number_of_maxima_7 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 312 | 0.0 | 1.0 | 1.0 | 1.0 | 905.550165 | 912.787630 | 0.097776 | 0.001001 | -1.482374e-08 | 0.999061 | ... | 4.552744 | 5.153861 | 0.0 | 2.424424 | 10.368385 | 6.428906 | 6.061785 | 4.893105 | 8.329089 | 5.141784 |
| 511 | 0.0 | 1.0 | 1.0 | 1.0 | 914.901319 | 927.126123 | 0.102501 | 0.001001 | -4.343774e-08 | 0.999013 | ... | 4.550446 | 5.160369 | 0.0 | 1.608737 | 9.560575 | 4.402903 | 3.702528 | 2.593091 | 6.365235 | 5.600553 |
| 607 | 0.0 | 0.0 | 0.0 | 1.0 | 967.790964 | 959.704184 | 0.040628 | 0.001001 | 1.363993e-07 | 0.999321 | ... | 4.250439 | 4.918822 | 0.0 | 1.803152 | 8.261652 | 3.685940 | 3.680112 | 2.786459 | 4.417432 | 5.216763 |
| 811 | 0.0 | 0.0 | 0.0 | 1.0 | 963.611859 | 966.760355 | 0.038524 | 0.000993 | -3.868799e-06 | 0.999117 | ... | 4.871424 | 5.586094 | 0.0 | 1.525412 | 7.275725 | 3.918884 | 3.886348 | 3.085988 | 4.900854 | 5.052743 |
| 905 | 0.0 | 1.0 | 0.0 | 1.0 | 940.638854 | 934.911722 | 0.076747 | 0.001001 | -3.821096e-08 | 0.998712 | ... | 4.235639 | 4.863876 | 0.0 | 1.529394 | 8.000601 | 4.259319 | 4.081086 | 3.478502 | 4.963320 | 4.796128 |
5 rows × 4734 columns
[ ]: